
HustBase完成
经过一个月的胡乱操作,这个数据库总算是按照预期地跑了起来。
¶主要工作
- 提供了数据定义功能:定义数据库、系统表、数据表、索引。
- 提供了数据库操作功能:创建、打开、关闭、删除数据库。
- 提供了数据表操作功能:创建、删除数据表。
- 提供了索引操作功能:(部分)创建、删除索引。
- 提供了按条件记录操作功能:插入、修改、删除数据表中的记录。
- 为查询模块提供部分语义分析功能。
- 编写部分用户界面模块功能。
¶遇到的问题
编写模块的过程中,主要出现了以下几个问题:
-
对MFC、Windows API的不熟悉
MFC实在是极其古老的东西,可以说早就停止支持,但本沿袭了十年的工程中仍然大量使用,尤其是HustBase.cpp中不得不使用。关于MFC的文档缺乏系统性和本地化,阅读起来较为困难。
如今的Windows开发基本上是用.NET Framework和C#进行的,C++的实现非常佶屈聱牙,仅仅是启动一个选择路径的窗口就要耗去一整天时间搜集资料。类似的过程,加上对C++遗忘较多,让我在开发初期花费了大量时间。
-
稳健性的缺失
数据库管理系统需要考虑的东西是比较多的,各种奇怪的情况层出不穷,这就需要在编程之前充分考虑。另外由于C++语言本身既有严格性又有不安全性,导致许多细小而严重的错误难以被快速检出,造成匪夷所思的执行结果。这也引发了最严重的下一个问题。
-
内存分配的错误
在对系统管理模块进行的测试过程中,我们常常遇到极为“神秘”的问题:所有的功能都能按照预期实现,但在一个随机的时间节点,或是对
RM_FileScan*等进行free操作时会引发“堆损坏”错误,即HEAP CORRUPTION DETECTED。一开始我以为这是HustBase框架本身的问题,因为任务书中指定的开发环境应为VS2010,而我使用的是VS2019。但其他同样使用VS2019进行开发的小组并没有出现同样问题,于是我们认为这是由某处访问越界造成的,尤其是早期版本中我使用了大量的
memcpy( )函数,这很容易造成访问越界。但当我逐渐用strcpy( )或严谨的指针操作取代memcpy( ),并且对所有写内存操作进行检查后,该问题仍然存在。最后我们发现,这个问题出现在内存分配时:
1
FileScan = (RM_FileScan*)calloc(1, sizeof(FileScan));
在
sizeof( )中,我错误地填写了FileScan,而非其作为指针指向的RM_FileScan结构体。因此,这一语句为指针分配了一个指针本身长度的内存空间,即4字节。但后面我将一个结构体填入了这块内存空间,这造成了越界。由于对
FileScan的内存分配几乎在系统管理模块的每个功能函数中都需要使用,这才使无论使用什么功能,都会随机出现该错误。对内存进行操作时,看清楚自己在写什么东西太重要了!
¶总结
本次综合能力培养实验时间跨度较长,任务较为复杂繁重。
实验开始时,我们野心勃勃,觉得数据库很简单,特别是由于已经有了较为全面的代码框架,我们认为可能只需要一两个“良好的夜晚”就能实现大部分功能。但显然这是不现实的,实际的开发过程远比想象中“痛苦”。分小组开发的方式让我进一步熟悉了使用Git进行协作的流程,也让我体会到了何谓“1 + 1 < 2”。组员LLGZONE由于还有实习工作在身,压力更是巨大,这使得我们的工作进度常常难以对接。
最终我们度过了艰难的一个月,开发出了一个具有一定“鲁棒性”,但功能还不太完善,没有多表连接查询,也没有完善地接入索引的数据库管理系统。好歹,It works,我们看这是好的,并且没有任何坏处。
这次我们没有使用GitHub,而是使用了国内的Gitee码云进行版本控制,由此也感受到了“另一种选择”——其用户体验确实非常良好。
总之,这里应该引用Linus Torvalds所说的名言:
(* 咏 唱 开 始 *)
所以,如果以后数据库综合能力培养实验还要做下去,并且想要做得好,请不要再使用目前沿用了十年的MFC代码框架了。
¶梦想封印 Enterprise v0.0.1-alpha
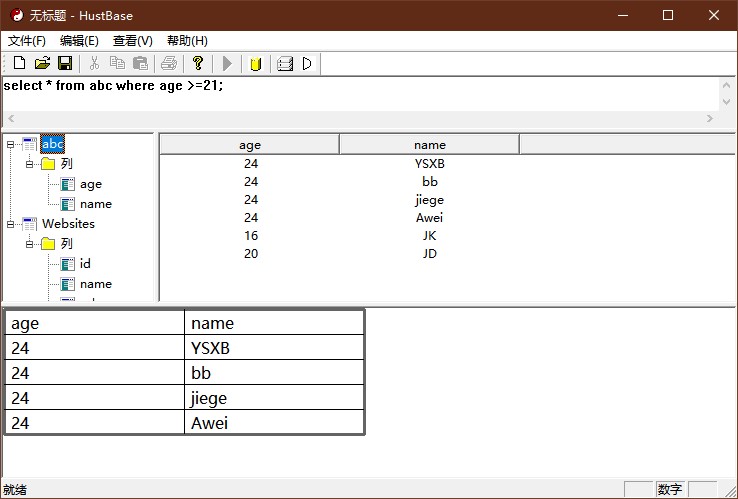
基于HustBase的大型民用数据库管理系统梦想封印 Enterprise的第1个技术预览发行版。
注意:
此版本尚不支持有条件多表查询和索引操作。