
从ANSI编码是啥说起
在 Windows 记事本的语境中:
所谓的「ANSI」指的是对应当前系统 locale 的遗留(legacy)编码。
梁海的回答 - 知乎
¶所谓编码
也许你曾试着购买东方Project正作游戏,或别的什么非英语内容:

扔进光驱,兴冲冲安装之后,点开附带的omake.txt文档,你会发现和安装时就遇到的一样,大部分成了乱码:
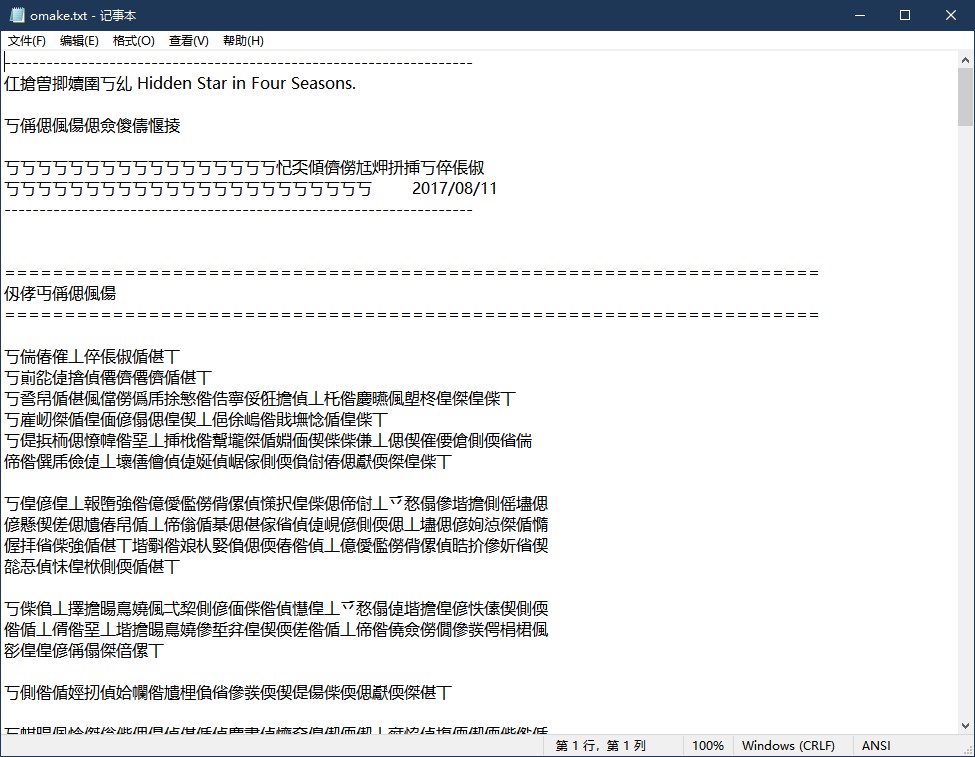
奇怪的是,英文、数字、以及一些符号部分并没有变成乱码,这时你就明白,该死的编码问题又出现了。一直到几年前,Windows记事本的默认编码都是写在右下角的ANSI(现在已经是UTF-8),这是什么编码呢?
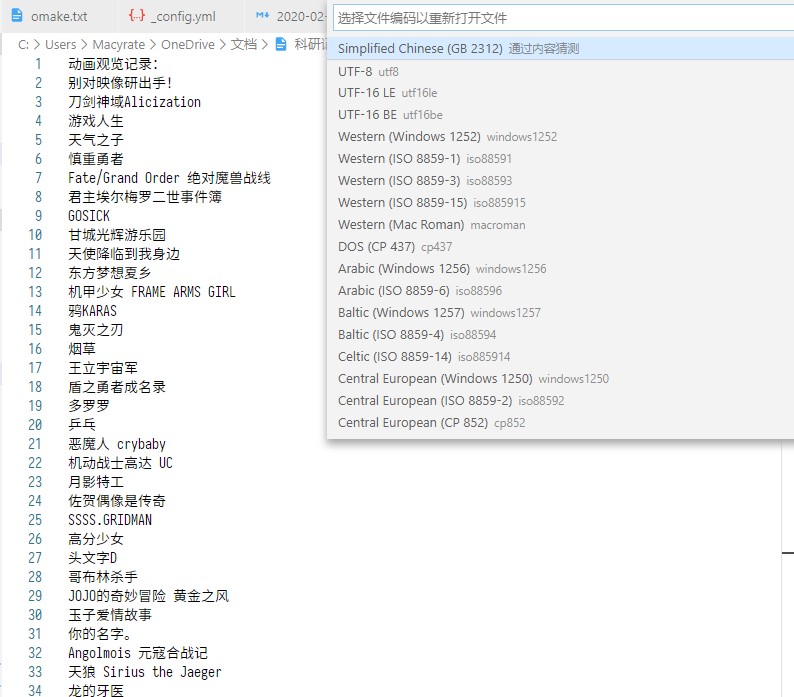
当你在简体中文Windows环境下用记事本写一个ANSI编码的文件,再用VS Code这种对各种编码都支持良好的编辑器打开它,编辑器所识别的编码是中国的国标码GB 2312。
而日本的“国标码”是Shift JIS编码,前面提到的omake.txt是不是用这个编码写成的呢?
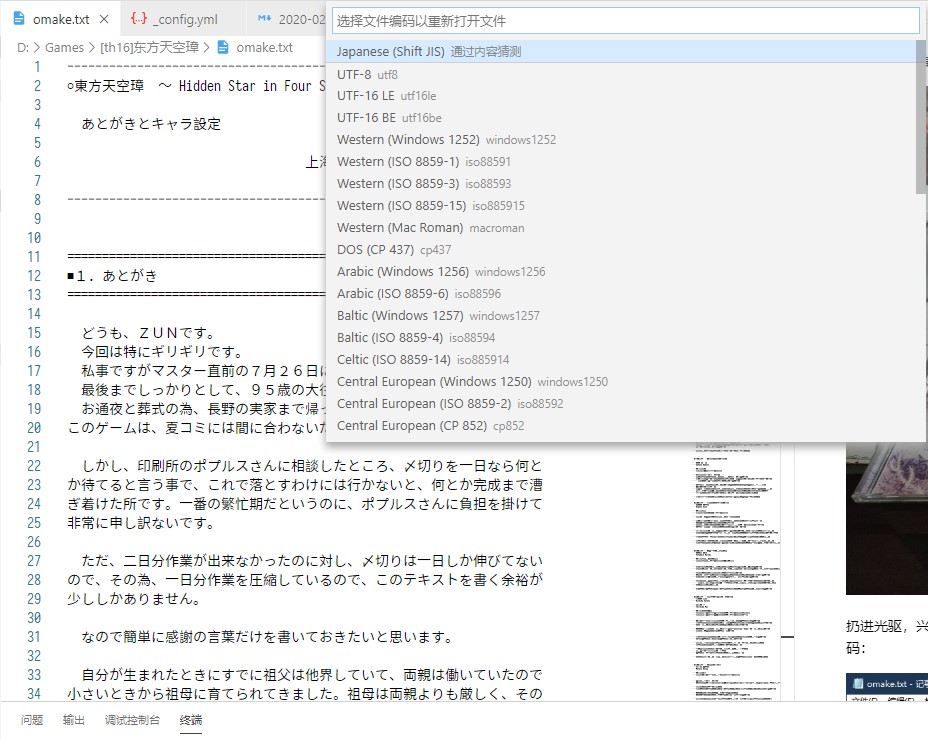
答案是肯定的。
为什么同样写着ANSI,实际上却是不同的编码?
花了一上午搜集了些资料,发现这个问题背后的故事远比想象中复杂,接下来就整理整理。
¶梦回1963
¶ASCII
这段历史故事要从计算机的“蛮荒”年代1963年开始说起。
ANSI指的是美国国家标准学会。1963年时的ANSI还叫作ASA(美国标准协会),以电报码为基础制定了大名鼎鼎的ASCII(美国信息交换标准代码)编码。这套编码共有128个字符,由7位二进制进行编号。ASCII的0~31号,再加上最后的127号“Delete字符”是33个不被显示的“控制字符”,其余95个字符正好与标准键盘符合。
可以对着键盘计算一下:数字行有10个数字键和3个符号键,字母行有26个字母键和8个符号键。而每个键都可以用Shift表示两个字符:
(10+3+8+26)*2 = 94
怎么还少一个?因为010 0000的“空格”也是一个字符,与000 0000的“空字符”并不等同,所以一共就是ASCII中的95个可显示字符。
¶EASCII
ASCII虽短小精悍,符号可能足够美国的电报系统使用,但要在计算机世界推行开来就有两个问题(我口胡的):
- 计算机的存储需要“对齐”,编码位数如果是2的整数幂,如8位会更方便、效率更高。而ASCII只有7位;
- ASCII没有法语德语等所包含的衍生拉丁字母,难以在欧洲实行,符号也不够全。
因此在70、80年代,EASCII(延伸美国标准信息交换码)应运而生,通过把ASCII扩展到8位,就又可以加入128个字符。但EASCII没有形成统一的标准,而是有数种互不兼容的方案,这里讲两个影响力较大的:
¶Code page 437
这是由IBM制定的标准,在1981年发布的原始IBM PC上采用。它扩展了衍生拉丁字母、希腊字母和一些表格符号等,还将ASCII中那些已被弃用却无法显示的控制字符做成了一些特殊符号,如很具有标志性的两个笑脸——0x01和0x02。设计思路基本来自于当时与IBM分庭抗礼的王安电脑。
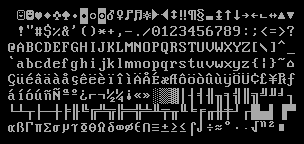
由于后来IBM PC的巨大成功以及微软和IBM之间的渊源,这套标准在MS-DOS里流传下来,这也就是我们在使用DOSBox的汇编实验里,在Borland Turbo Debugger中所见到的:
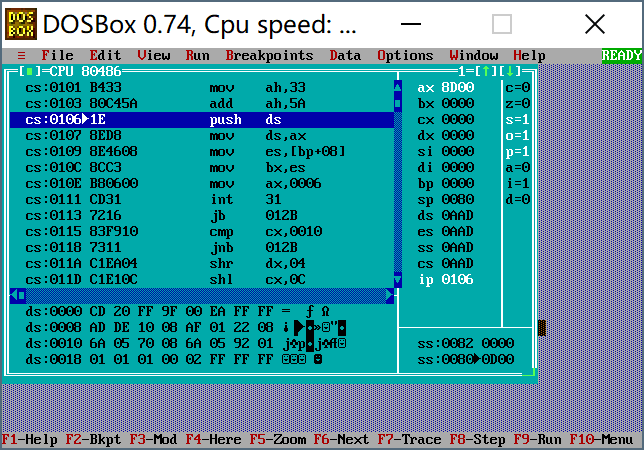
¶ISO/IEC 8859
这个8位字符集标准由ISO(国际标准化组织)及IEC(国际电工委员会)联合制定,其中包含ISO/IEC 8859-1到ISO/IEC 8859-16,但没有12号的15套扩展方案。而每一套方案就是扩展了一个地区的语言符号。这里贴出扩展了西里尔字母的ISO/IEC 8859-5:
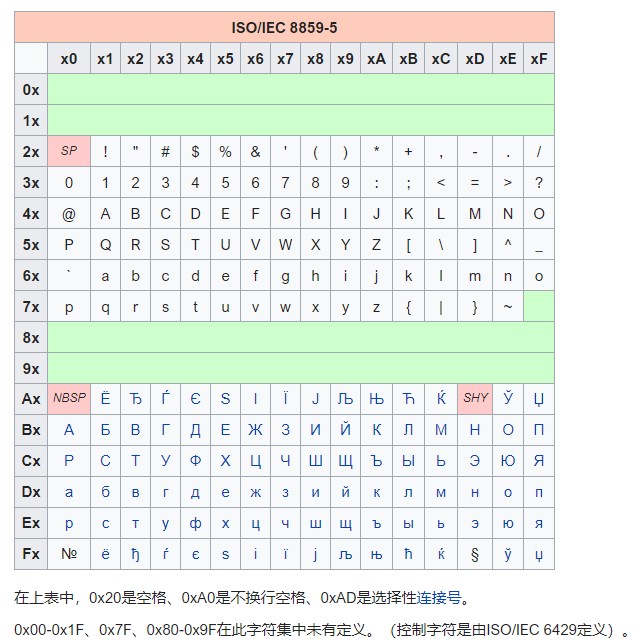
这项工作最早并不是由ISO和IEC启动的,而是由ANSI和ECMA(欧洲计算机制造商协会)。他们于1985年公布ECMA-94,即后来的ISO/IEC 8859 parts 1, 2, 3, 4。
80年代雄霸西方,如今却只能在敖厂长的视频里见到的Commandore 64使用的就是ISO/IEC 8859,这也见证了那个IBM、苹果、Commandore、雅达利群雄并起的时代。
另外需要提及的是Windows-1252,即Code page 1252,这是西方文字版本Windows(而不是MS-DOS)中默认的字符集,是ISO/IEC 8859-1的超集。虽然并非是真正的ANSI标准或ISO标准,但却是最流行的。在微软投向国际标准化、Windows普及开来之后,Code page 437也就逐渐消失了。
¶东方宽字符
80年代计算机在汉字文化圈逐渐流行时,情况又不妙了起来:汉字数量太多,一个字节的8位也不够用了。那么就用两个甚至多个字节来表示一个字符吧,这就是所谓的“宽字符”。不过东方世界的剧情稍有变化,因为此时已有ISO/IEC 2022这一技术规范指导东方文字的编码。中国大陆由此制定了包含6763个汉字的国标码GB 2312,覆盖了绝大多数使用环境。许多生僻字没法处理,于是后来又制定了加入更多汉字的GBK,即国标扩展。但GB 2312留下来的坑一直遗留到最近几年,让名字里有生僻字的人乘飞机或办手续都麻烦不少。
日本产业标准调查会JISC也根据ISO/IEC 2022进行了一系列骚操作,最终形成了Shift JIS。通行于港澳台的Big5也于此时诞生。
微软要在系统里支持这么多种编码,只好使用Windows code page这个值(可以用chcp命令查看)来代表当前系统的编码标准。可能这些五花八门的编码基本都发源于ISO/IEC,往上再追溯一下就到了ANSI的ASCII,于是微软模糊地用ANSI来概括了这一切,即我们在Windows中所看到的ANSI并不是某种特定的编码,而是当前区域所使用的编码标准。Windows简体中文系统的Code page是936,早期对应的是GB 2312,在Windows 95之后成为了GBK。而前面所见的Code page 437和Code page 1252也都是这套玩意的一部分。
Code page代码页的机制也体现在Linux中,只是Linux没有“ANSI”这种不科学不严谨的Windows特色表述。而且Linux诞生于1991年的近代,许多历史包袱大可以免去,很快也就支持了Unicode。
啊,Unicode当然才是最重要的一页。
¶Unicode拯救世界
这种乱七八糟的情况持续到80年代末,无论是ISO还是业界都看不下去了。ISO于1988年开始制定ISO 10646通用字符集;几乎与此同时,Apple和Xerox等软件制造商组成Unicode联盟,开始制定Unicode。但他们发现如果两边各自为政,世界又会再次分裂,就像已经对立了几十年的美苏冷战;于是他们开始合作,ISO 10646和Unicode最终基本成了同一样东西——所有的字符都在相同的位置并且有相同的名字。
Unicode编码点分为17个平面(plane),每个平面包含2^16(即65536)个码位(code point)。17个平面的码位可表示为从U+xx0000到U+xxFFFF,其中xx表示十六进制值从0x00到0x10,共计17个平面。
1991年,Unicode 1.0.0横空出世,几乎整合了所有西方字母文字;
1992年,中日韩统一表意文字(CJK Unified Ideographs)被定义并加入Unicode。
此后,开放合作、兼容并包成为天下大势,几乎所有能被形容为“现代”的计算机世界物体都支持了Unicode,Unicode本身也在不断发展,不再是一个单纯的“编码”,而是一种标准,包含了Unicode编码方式和多种实现方式,即所谓的Unicode转换格式UTF。你现在所看到的这个网页,使用的就是UTF-8编码实现方式。
关于Unicode的更多内容,这里有一篇讲的很清晰的文章:
细说:Unicode, UTF-8, UTF-16, UTF-32, UCS-2, UCS-4
¶“字符集”与“编码”
前面说了这么多,表述中又有“字符集”(character set),又有“编码”(character encoding),它们到底区别在哪?
“字符集” 当然是字符的“集”,是各种文字和符号的总称。这指明了有哪些字符是被需要的,以及它们长什么样(字形)。不少汉字在不同区域有不同的写法,字形不统一的情况下如何取舍,就属于字符集的范畴。
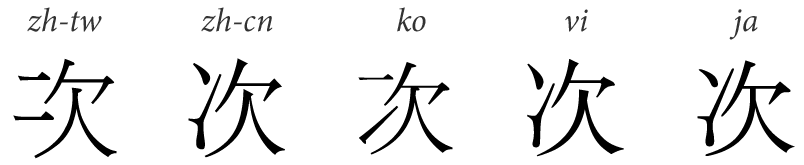
“字符编码” 是将字符集中的每一个字符都用一串二进制数表示的方法。当我们谈论GB 2312时,我们所说的其实是GB 2312字符集,以及用于对其进行编码的EUC-CN编码方案,这两个事物组合起来才是所谓的“GB 2312编码”。Unicode最“正统”的编码方案是UTF-32,但结合二八定律还是UTF-8更加实用,因此“Unicode编码”的说法是不准确的,所谓的Unicode更像是字符集。
¶U+5F41 彁
最后,又要首尾呼应地回到东方Project。
彁,这是前面所说的Shift JIS形成的早期,被1978年通商产业省制定的JIS C 6226错误收录的29个不存在的“幽灵汉字”之一。这些汉字一时不知读音、含义也不知具体出典,令人迷惑。
| 幽灵汉字 | ||
|---|---|---|
| 垉(52区21点) | 垈(52区18点) | 墸(52区55点) |
| 壥(52区63点) | 妛(54区12点) | 岾(54区19点) |
| 彁(55区27点) | 恷(55区78点) | 挧(57区43点) |
| 暃(58区83点) | 椦(59区91点) | 橸(60区81点) |
| 汢(61区73点) | 熕(63区80点) | 碵(66区83点) |
| 穃(67区46点) | 粐(68区68点) | 粭(68区70点) |
| 粫(68区72点) | 糘(68区84点) | 膤(71区19点) |
| 蟐(74区12点) | 袮(74区57点) | 軅(77区32点) |
| 鍄(78区93点) | 閠(79区64点) | 靹(80区56点) |
| 駲(81区50点) | 鵈(82区94点) |
1997年,日本对这29个字进行了深入的调查。他们发现其中一些字来自名字极生僻的地名,如静冈县的石橸(いしだる),另一些是被误写、误认的错别字,如“𡚴”被记成了“妛”……最终,29个幽灵汉字中有28个成功找到了来源,“成佛得脱”。
唯独彁字,跨越不知多少年,仍然是个谜。
但它就此被保留下来,从JIS C 6226到Shift JIS,到CJK,最后成为Unicode中的“U+5F41”,成为全世界计算机中不可分割的一部分。
也许这个字确实存在其出处,但在这数十年间终于连其最后的出典也散佚。如今留下的只有这永存的痕迹,作为描绘“现实”的字符集中唯一的“幻想”,与相信着车库中有喷火龙的人类一起迈向宇宙的终焉。