
C#杂记之伍:数组与集合
数组可以说是在任何语言中都非常基本的数据结构了。这篇笔记以C#中的数组为引,再延伸到C#的几种集合类(Collections)以及一些相关的基本概念。
¶数组 Array
¶概述
数组存储相同种类的元素,其大小固定,且是顺序存储的,即在内存中占据一段连续的地址。
数组作为一种引用类型(其基类是System.Array),需要用new来创建实例。
//初始化时指定大小
double[] balance = new double[10];
//可以直接赋值来初始化
int[] marks = {99, 98, 92, 97, 95};初始化而尚未赋值的数组,编译器会根据其类型隐式地将所有元素设置为默认值。
数组最大的特点还是能够用下标索引来随机访问其中的元素:
double salary = balance[9];
//以下是C# 8.0引入的好东西!
//末尾运算符 ^
//[^n]表示[length-n],类似Python用负数索引[-n]表示[length-n]
double salary = balance[^1];
//范围运算符 ..
//[a..b]表示从[a]到[b]的范围(但不包含[b]!),类似Python的切片[a:b]
//省略a代表0,省略b代表^0
double[] salaries1 = balance[..^3];
//如果a比b还大,会抛出异常(Python中则是返回空列表)
double[] salaries2 = balance[3..2]; //ArgumentOutOfRangeException
//a和b一样大时,返回长度为0的集合
double[] salaries3 = balance[3..3];
Console.WriteLine(salaries3.Length); //0由于实现了IEnumerable接口,数组可以使用foreach...in...的方式进行迭代访问,还可以使用LINQ,这样就无需获取数组长度再用for循环迭代了。关于这个接口及其相关的内容,我在本文稍后的部分记述。
¶索引器 Indexer
索引器(Indexer)可以让各种类、结构、接口实现数组的这种能够用下标索引来访问的功能。
索引器就像一个名为this的属性,可以用访问器进行定义。
访问器是可在属性上定义的两个方法。其中get方法在读属性时执行;set方法隐含一个传入的
value参数,在写属性时执行。一个常见的用途是用公开属性的访问器来对私有属性进行读/写。另外也可以在set访问器里对传入值进行范围检查等操作。
索引器的一般定义示例:
element-type this[int index]
{
// get 访问器
get
{
// 返回 index 指定的值
}
// set 访问器
set
{
// 设置 index 指定的值
}
}比较神奇的是,索引器的索引下标并不是只能使用int,还可以用string。同时索引器又像是一个方法,甚至可以重载,这意味着你可以同时定义以int和string作为索引下标的索引器。
¶多维数组
C#的多维数组在定义时,维度之间用逗号隔开。
//三维数组
int[, ,] array3Da = new int[2, 2, 3] { { { 1, 2, 3 }, { 4, 5, 6 } },
{ { 7, 8, 9 }, { 10, 11, 12 } } };¶交错数组
交错数组是数组的数组。当我们说“数组”的时候,说的是一个引用类型。因此交错数组与多维数组的不同之处在于,它本质上是个一维数组,其元素为引用类型,且被初始化为null。
也正因此,交错数组中的元素只需要是规定的数组类型即可,不需要具有一致的长度:
//包含大小不同的三个二维数组元素的一维交错数组:
int[][,] jaggedArray = new int[3][,]
{
new int[,] { {1,3}, {5,7} },
new int[,] { {0,2} },
new int[,] { {11,22}, {99,88}, {0,9} }
};
System.Console.Write("{0}", jaggedArray4[0][1, 0]); //输出:5¶集合 Collections
¶概述
集合类是定义在System.Collection命名空间里的几种类。比起数组,它们实现了几个接口,能更方便用于存储和检索数据。
为了支持无数种类型,非泛型集合把所有的元素都装箱成object类的对象来存储。元素的读写总要涉及到装箱与拆箱,在性能上有一定损失;而且也因为装箱,你可以把任意不同类型的元素装进同一个集合,这是危险的,相当不妙。
因此,在引入对泛型的支持后,更好的选择是使用命名空间System.Collection.Genreric里的泛型集合来存储数据。以下是几种非泛型和泛型集合:
| 非泛型集合类 | 泛型集合类 | 描述 |
|---|---|---|
| 动态数组 ArrayList | 列表 List<T> | 具有动态大小的数组 |
| 哈希表 Hashtable | 字典 Dictionary<Tkey,Tvalue> | 由键-值对组成的集合 |
| 排序列表 SortedList | 排序列表 SortedList<Tkey,Tvalue> | 和字典相似但有排序功能 |
| 队列 Queue | 队列 Queue<T> | 先进先出(FIFO)队列 |
| 堆栈 Stack | 堆栈Stack<T> | 后进先出(LIFO)队列 |
而泛型集合中,最常用的是List<T>和Dictionary<Tkey,Tvalue>,其它的集合基本都建立在其基础上。
¶列表 List<T>
¶概述
上面的表格里写到,List<T>是泛型版本的ArrayList,是具有动态大小的数组。也就是说,其原理依然是顺序存储的数组,具有随机访问快但插入删除较慢的特点。
C#里有没有用双向链表实现的链式存储数据结构呢?也是有的,它就是LinkedList<T>,只不过很少有人会用到,毕竟随机访问速度在大多数场景下更加重要。
¶创建
要创建一种类型的列表,依然需要用new:
List<Animal> animalCollection = new List<Animal>();¶容量
List中有两个int属性:Count和Capacity。
Count代表List中现有的元素数量,而Capacity代表List的容量。当Count达到Capacity的值,再试图加入元素时,Capacity就会自动进行调整。下面是在一个List<int>中加入600个元素的结果,其中白色数字代表现有元素数量Count,绿色数字代表List容量Capacity:
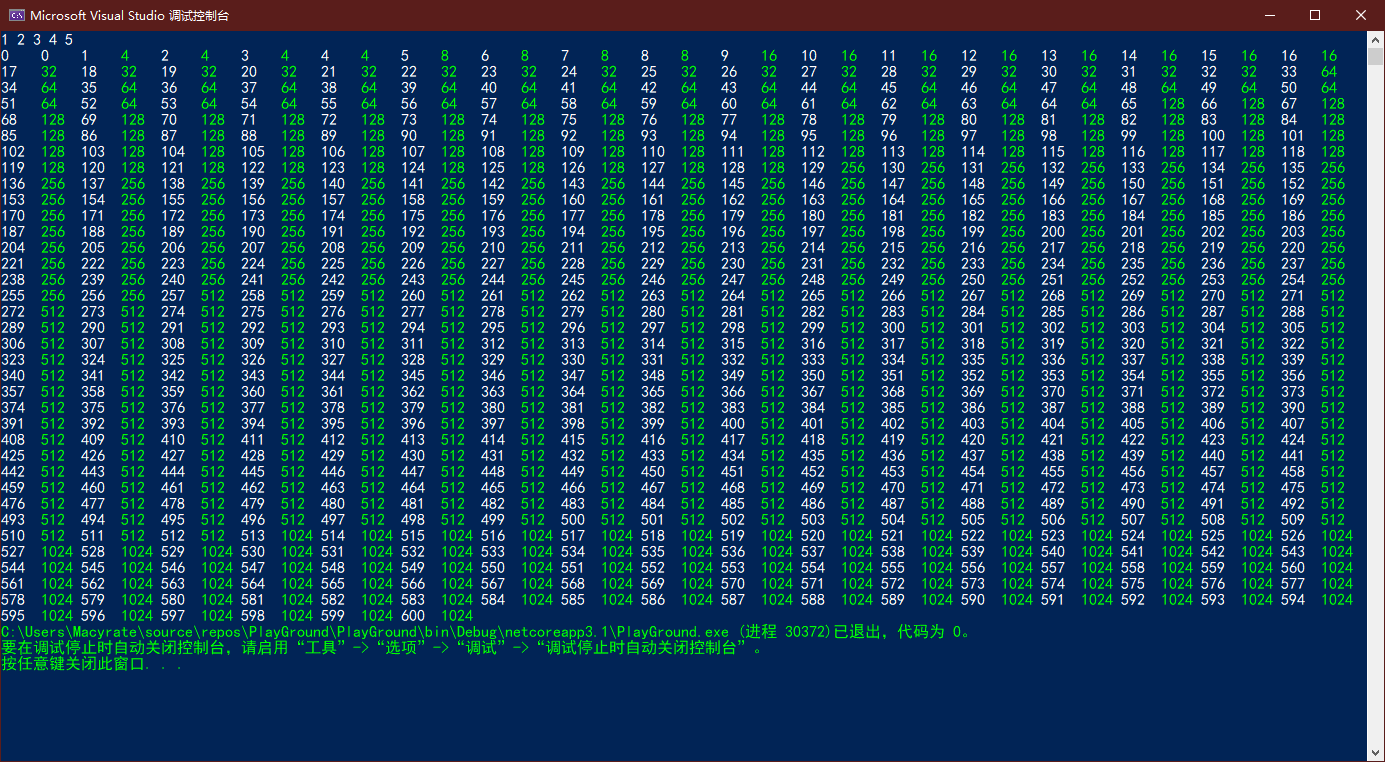
可以看出,加入第一个元素时,Capacity从0被调整到4。之后每次Count要超过Capacity时,Capacity就会翻倍,以容纳更多元素。这个容量调整算法不是固定的,比如对于Dictionary<Tkey,Tvalue>来说,每次调整增加的容量都是质数。虽然不知道为什么要这样设计,但奇怪的知识增加了!
除了让其自动增长之外,还可以直接访问Capacity,手动设置为不小于当前Count的值;也可以调用List的TrimExcess()方法,将Capacity直接削至Count的值。不过考虑到开销,如果未使用的容量小于总容量的10%,则不会对容量进行调整。下面是在加入了300个元素后,调用TrimExcess()(用黄色字体表示),再加入300个元素的效果:
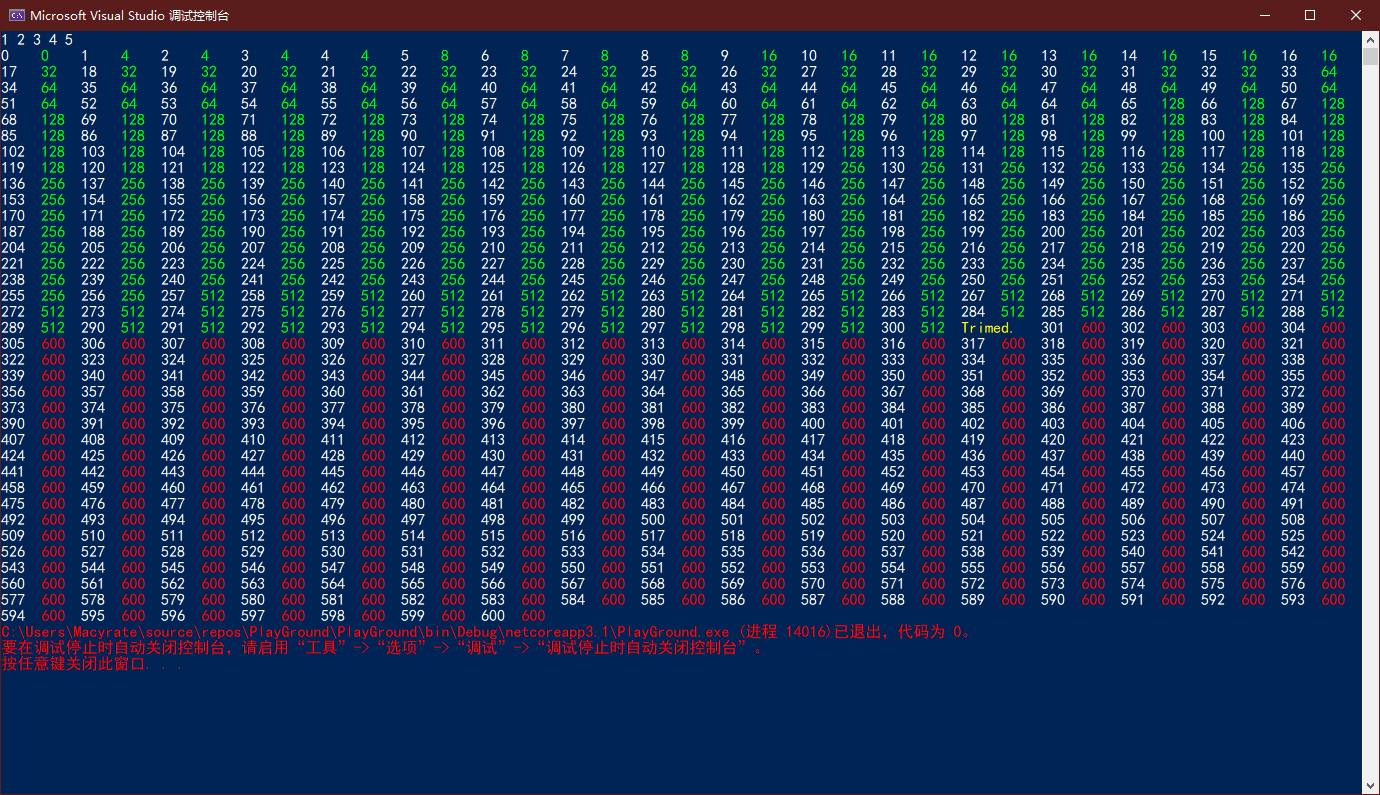
手动设置Capacity有什么用呢?毕竟就算设置了,由于Capacity的自动调整机制,还是能不受限制地往里添加元素。而且在调整Capacity时,还会有复杂度为O(n)的计算,这是因为List<T>仍然基于顺序存储,调整Capacity必须在内存中重新划分一块区域,再把元素复制进去。关于手动调整Capacity的意义我依然存疑,如果你知道,请告诉我!
¶增
- Add() 在末尾动态加入元素
- AddRange() 在末尾添加一个集合中的元素
- Insert() 在指定索引处插入元素
- InsertRange() 在指定索引处插入一个集合的元素
¶删
- Remove() 删除第一个内容匹配的元素
- RemoveAt() 删除指定索引处的元素
- RemoveRange() 删除一定范围内的元素
- RemoveAll() 删除所有条件匹配的元素
- Clear() 直接清空
¶改
依然可以直接用下标索引访问:
animalCollection[0] = cat;其原理是List类用Item()方法作索引器。
但要注意,List的长度是其Count属性的值。对于新建的List,没有任何元素,Count为0,甚至不能用0号索引来访问并赋值。应该先用一些方法让索引对应的位置可用。
List<Animal> animalCollection = new List<Animal>();
animalCollection[0] = cat; //这是错误的,0号元素还不存在
List<Animal> animalCollection = new List<Animal>(new Animal[10]);
animalCollection[0] = cat; //这是可以的,创建List时填入了10个null¶查
- Contains() 判断List内是否有内容匹配的元素
- Exists() 判断List内是否有条件匹配的元素
- Find() 查找并返回第一个条件匹配元素
- FindAll() 查找并以List的形式返回所有条件匹配元素
- IndexOf() 查找第一个内容匹配的元素,返回其索引(可以用重载指定搜索范围)
- LastIndexOf() 查找倒数第一个内容匹配的元素,返回其索引(可以用重载指定搜索范围)
- BinarySearch() 用指定的比较器在一定范围内二分查找元素,返回其索引
¶字典 Dictionary<Tkey,Tvalue>
C#中的字典是泛型的哈希表(HashTable),存储的是键值对KeyValuePair<TKey, TValue>。
Dictionary<string, string> mydict = new Dictionary<string, string>();
//仍然是Add()添加元素
mydict.Add("lang1", "C++");
mydict.Add("lang2", "C#");
mydict.Add("lang3", "Python");
//CotainsKey()判断是否有该键,也有ContainsValue()判断是否有值
if(mydict.ContainsKey("lang3"))
mydict.Remove("lang3");
//根据TKey使用索引器,但访问前不检查可能会爆炸(KeyNotFoundException)
//WriteLine(mydict["lang3"]);
//TryGetValue()尝试用key获取value,没获取到的话传出null,本身返回False
WriteLine(mydict.TryGetValue("lang4", out string test));
WriteLine(test);¶队列 Queue<T>和堆栈 Stack<T>
这两个就更没什么值得说的了,基本上是List<T>的“阉割”版。
对于它们而言,添加、删除元素并不是用Add()方法和Remove()方法。队列Queue<T>中,使用入队Enqueue()和出队Dequeue();队列Stack<T>中,使用压入Push()和弹出Pop()。
你也无法再使用索引随机访问Queue和Stack中的元素,必须遵守这两种数据结构的规则。能进行的操作非常有限,比如用Peek()访问队首/栈顶元素。
¶枚举器
说到枚举器,必须了解的是两个接口:IEnumerator和IEnumerable。
¶IEnumerable
所有的数组和集合都实现了这个接口,它们被称为可枚举类型。这也是数组和集合能进行各种操作,乃至使用LINQ的基础。这个接口里只有一个方法:
GetEnumerator()。
方法名很易懂,获取枚举器。C#中的“枚举器”,指的就是实现了接口IEnumerator的类型。
LINQ为IEnumerable接口添加了许多扩展方法,这一点在第C#杂记的壹和叁中我都有提到。其实由于LINQ用查询表达式写可读性更强,这些扩展方法里我觉得最有用的是ToList()方法,它可以把各种数组和集合都转换为万能的List<T>。特别地,对Stack<T>来说,调用ToList()后得到的列表是根据“后进先出”的出栈顺序排列的。
¶IEnumerator
如上所说,实现了这个接口的类型被称为枚举器。
枚举器的工作就是把元素一个个地吐出来(枚举)。这个接口用三个成员共同实现了类似链表的数据结构:
- Current:序列中当前位置项的属性,以
object?可空类型表示,故可以为任何类型。原始状态下这个属性不可用,访问时会抛出异常:System.InvalidOperationException:“Enumeration has not started. Call MoveNext.”
- MoveNext():将枚举器位置指向下一项,如果下一项是无效的,则返回False,表示枚举已经完成。
- Reset():把位置重置为原始状态。
实现了IEnumerable的可枚举类型,其能够使用foreach语句进行迭代的原理就是运用了枚举器:
class Program
{
static void Main()
{
int[] myArray = { 10, 11, 12, 13 }; // 创建数组
var ie = myArray.GetEnumerator(); // 获取枚举器
while (ie.MoveNext())
{
int i = (int)ie.Current; // 获取当前项
Console.WriteLine("{0}", i); // 输出
}
//用foreach进行同样的迭代
foreach(var i in myArray)
Console.WriteLine("{0}",i);
}
}¶比较与排序
众所周知,一切排序算法的基础都是比较。不同排序算法的复杂度之差异,就在于它们比较元素的次数。
C#中有两个接口用于实现比较:IComparable和IComparer。
看这两个接口的名字,就可以会猜测它们和上面在枚举器里说到的两个接口的关系一样。事实上它们之间有很大不同,但也有相似之处。
¶IComparable
实现了这个接口的类型是可比较类型,由它们组成的数组、集合是可以进行排序的。C#中有很多内置类型已经实现了这个接口,比如各种值类型、字符串、时间日期等等。
这个接口也只有一个方法:CompareTo()。
CompareTo()接收一个用于和this比较的参数,并返回一个int作为比较的结果。举个例子,如果定义了Person类,且为其实现IComparable接口:
class Person : IComparable
{
public string Name { get; set; }
public int Age { get; set; }
public Person() { }
public Person(string name, int age)
{
this.Name = name;
this.Age = age;
}
//实现IComparable接口
public int CompareTo(object obj)
{
if (this.Age == obj.Age)
{
return 0;
}
else if (this.Age > obj.Age)
{
return 1;
}
else
{
return -1;
}
}在此基础上,比较两个Person:
if(person1.CompareTo(person2) == 0)
{
WriteLine("Same Age.");
}
else if(person1.CompareTo(person2) > 0)
{
WriteLine("Person 1 is older.");
}
else if(person1.CompareTo(person2) < 0)
{
WriteLine("Person 1 is younger.");
}¶IComparer<T>
Comparer是“比较器”,对于那些没有实现IComparable接口的类,可以为其单独定义一个实现IComparer<T>的类。
接口中包含一个方法Compare()。它对两个T类型的对象进行比较,返回int作为比较的结果。这个接口也有非泛型版本,它能支持不同类型的对象之间的比较,这很神秘,可能一般不会用到。
用实现了IComparer<Person>的比较器对两个Person进行比较:
static void Main(string[] args)
{
Person person1 = new Person("张三", 24);
Person person2 = new Person("罗翔", 42);
int n = new PersonComparer().Compare(person1, person2);
}¶Sort()方法
Sort()方法运用集合中元素所属类型的默认比较方法,或指定的某种比较方法进行升序排序。
这个方法有四种重载:
- Sort()
无参形式,在元素对象实现了IComparable接口时可以使用。 - Sort(IComparer<T>)
以比较器为参数,需要定义比较器,并new一个传入。 - Sort(Int32, Int32, IComparer
)
在指定范围用比较器排序。 - Sort(Comparison
)
用委托进行排序,其中委托Comparison<T>接受两个同类型参数,返回int。原型:public delegate int Comparison<in T>(T x, T y);
这看起来并不够优雅,直接用LINQ的OrderBy()配合Lambda表达式来排序它不香吗?
据说OrderBy没法在Unity构建的iOS游戏上运行,所以必须得用Sort()。不过去它妹的,等真的踩了这个坑再说吧,现在先记在这里(笑)。
原本以为数组和集合是极为简单的东西,计划着能在一天内写完,结果坑越挖越多,中途也写了不少代码进行测试和验证,竟然也花了快一个星期。至此,C#入门级别最大的几块拼图几乎完成了。后面的坑还有装箱拆箱、特性、堆区与栈区内存、对象的构造与析构过程、垃圾回收机制、异步流式处理等等,慢慢填吧。